Day 7️ : Speed Optimization & The Power of Caching!
Welcome Back, Performance Hackers!
At this point, your app is growing, scaling, and handling more traffic than ever. 🎉 Everything seems perfect… until it isn’t.
One day, your founder storms into your workspace:
“The website is slow! Customers are complaining! Do something!” 😡
As a developer, you:
✅ Check CDN — Everything looks fine.
✅ Load the homepage — Speed seems okay.
✅ Open product pages — BOOM! 💥 It takes forever to load! why??
Time to investigate! 🔎
🔎 The Root Cause: Slow API Calls
Using network logs, you discover that:
- Fetching images? Fast (served from CDN).
- Fetching product details? SLOW! (served from the database).
The issue? Product details are coming directly from the server every time! As user comes on the product page, browser makes the api request but the query is really slow, that is why its taking a lot of time to populate the products data.
Question? How to reduce the latency?
Solution? Bring data closer to the user!
⭐Fundamental approach to reducing a latency in computer science is getting data that a system needs close to it.
🚀 Speeding Up Data Fetching with Caching
1️⃣ Frontend (Browser) Caching
Instead of fetching product data every time a user visits a page, we:
✅ Pre-fetch data when they visit the homepage.
✅ Store data in the browser (localStorage/sessionStorage).
📌 Result? The product page loads instantly! cause the request is already resolved. We already have the data to show on product page.
This concept of taking a temporary copy of the data and storing somewhere for low latency is called caching.
Here we did browser caching, we have more better option …
2️⃣ Server-Side Caching (Faster API Calls)
The goal is still same, having data to show on ui as fast as possible. So just like we stored data on browser, we can store on server as well.
Keep frequently accessed data as close to the request as possible.
🔹 Every time a user requests product data, instead of querying the database, we store it in server memory for a short time.
🔹 The next time a user requests it, we serve it instantly from memory.
🛠️ Tools for Server-Side Caching
- Redis (Best for key-value caching)
- Memcached (Fast but volatile)
- Varnish Cache (For web acceleration)
📌 Result? 🚀 API calls are 10x faster!

💡 What’s the Best Caching Strategy?
Your founder understood the caching, but he is confused about
how can I store this data down the server ?
We can store it as a map. we can store it as a key which is product id then you have a value next to it so in a map. You have a key and a value of the product id and then you have all the data for the product to store this map. it’s quite safe But there are libraries out there in the world.
There are two ways to store data. Lets Understand them.
1️⃣ In-Memory Cache (Super Fast, but Limited)
Assume So if your architecture has 6 small servers, so all 6 servers will be storing the cache in memory and anytime they get any request, they will serve the cache data as response.
The benefit of this is that this cache is extremely fast the moment you get a request all the server has to do is to go and fetch a line from its cache memory so this would be in microseconds
- Each server keeps its own cache.
- If one server fails, its cache disappears.
- Data consistency issues if multiple servers hold different cache copies.
Data consistency ensures that all servers show the same updated information. For example, if a user places an order for a T-shirt and the stock was originally 10, it should be reduced to 9 everywhere. However, if only one cache server updates the stock to 9, while others still show 10, a consistency issue arises. This means some servers might still allow orders based on the old stock count, which can lead to overselling and inventory mismatches.
📌 Use when: You need ultra-low latency and can afford occasional data inconsistencies.
2️⃣ Centralized Cache (Better for Large-Scale Apps)

- A dedicated cache server (Redis/Memcached) stores all cached data.
- All application servers query this cache first before hitting the database.
- No duplication of cached data across servers.
📌 Use when: You need consistent data across multiple servers.
📊 Choosing Between In-Memory vs. Centralized Cache

📌 Final Decision? ✅ Use a centralized Redis cache for our app.
🛠️ Scaling Caches: How Do We Distribute Data?
With millions of products, a single cache server won’t be enough.
💡 Solution? Use Multiple Cache Servers!
Additionally, we need to distribute the load to all the multiple cache servers. There are certain issues with the data, lets look all the possible cases.
🔹 Option 1: Replication (Each Cache Stores Everything)
✔️ High availability
✔️ Each server has full product data
❌ Lots of data duplication
Thoughts 💭: ⚠️ Never gonna use this, so much data duplication. Already terrifying.
🔹 Option 2: Sharding (Each Cache Stores Different Data)
Sharding is the process of dividing a large dataset and distributing it across multiple servers based on a specific property to improve performance and scalability.
For instance, So in our cache servers, to speed up product searches. Instead of storing all product data in a single cache, we shard the data based on categories:
- Cache Server 1: Stores data for Electronics (e.g., Phones, Laptops, Cameras)
- Cache Server 2: Stores data for Clothing (e.g., T-Shirts, Shoes, Jackets)
- Cache Server 3: Stores data for Home Appliances (e.g., Refrigerators, Microwaves, ACs)
When a user searches for a laptop, the request goes directly to Cache Server 1, instead of scanning all data. This reduces query time, prevents overloading a single server, and ensures faster responses.
✔️ More efficient (Less duplication)
✔️ Faster queries
❌ Complex setup
📌 Final Decision? ✅ Use Sharding!
🔢 Sharding: How Do We Assign Data to Cache Servers?
To distribute product data, we need a consistent way to decide:
👉 Which cache server should store which product?
Another example is you can also say that this cache is going to be storing data only for the user ID from 1 to 200. This cache is going to be storing data only for user ids from 100 to 200 the next 200 right? There are assigned ranges. So basically we are assigning the ranges to the data that each cache server manages.

Also to avoid duplication we can use hashing.
🔢 Hash-Based Load Balancing
In hash-based load balancing, each product is assigned a unique hash value, which determines which cache server stores it. This ensures that all future requests for the same product are directed to the same cache server, improving efficiency and reducing unnecessary lookups.
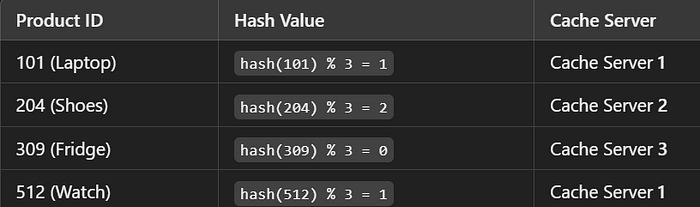
Assume our app has three cache servers that store product data. Instead of randomly assigning products to servers, we use a hash function to determine their placement.
How it works:
- Generate a hash value for each product based on its unique ID.
- Map the hash value to a specific cache server (e.g., using
hash(productID) % number_of_servers). - All future requests for the same product go to the same cache server, ensuring fast retrieval.
Product Distribution Across Cache Servers:
Benefits of Hash-Based Load Balancing:
The benefit of this is that, since the hash is constant, since the hash of product ID cannot change because the product itself cannot change. The cache server that is going to respond to this request as always going to be the same. So there won’t be any duplication of product data between the caches. Amazing right ?
✅ Efficient storage and retrieval — Requests for the same product always hit the same cache server.
✅ Even distribution of data — The hash function ensures products are spread across cache servers.
✅ Scalability — New products are automatically assigned based on the hash function.
- This is great; So we are able to horizontally scale up our cache.
- We are able to load balance in our cache.
- We are using two fundamental concepts of computer science together (sharding and hashing).
📌 Result?
🚀 Efficient data distribution
⚡ No duplicate cache data
✅ Load balanced across multiple cache servers
🏆 Final Takeaways from Day 7
✅ Browser caching speeds up page loads.
✅ Server-side caching (Redis) makes API calls 10x faster.
✅ Sharding & Hashing distribute cache efficiently across servers.
✅ Caching = Lower database load + Faster response times!
Great!! See you in the next blog.
