Day 8: Mastering the Art of Caching — Like a Pro!
🎉 Welcome to another day of breaking down complex systems in the simplest way possible!
In our previous blog, we learned why caching is essential and explored different caching strategies like:
✅ Browser-side caching — Keeping frequently accessed data close to users.
✅ Server-side caching — Storing responses in a central cache to speed things up.
✅ Sharding & Hashing — Distributing data efficiently across multiple cache servers.
And So we have now multiple cache servers in our architecture, and each server serving limited product data to our backend.

What happens when a one of cache server fails?
Let’s say you have three cache servers (Server 0, Server 1, and Server 2), and suddenly, Server 1 dies. 💀

Boom! Every request that was supposed to go to Server 1 is now failing!
What do you do? 🤔 All the remaining cache server need to serve the data which cache server 1 was serving.
🚨 The Simple (But Inefficient) Fix
The easiest way to fix this would be:
✅ Case 1: Redistribute all the failed requests to the remaining servers.

✅ Case 2 : If a new server is added, redistribute the data again.

👉 The problem? Every time you add/remove a cache server, ALL cached data gets shuffled around. That means our servers will be constantly reloading from the database — which is SLOW.
In Case 1, data needs to be pulled from db to satisfy the lost cache server request.
In Case 2, some of the data from rest of the servers need to pulled out and sent to this new server, because now its going to manage some request. The overall load from rest of the system will reduce and it will migrate to this new cache. And that is a heavy operation.
Cache warmup and Cache readiness takes some time
📌 We need a better way! Enter…
🔥 The Magic of Consistent Hashing!
Instead of dumping and reloading all the data, we use an intelligent way to distribute requests among servers so that only a small portion of data moves when servers change.
The whole idea of consistent hashing is to reduce the amount of data migration of data loading you need when your system scales up or scales down.
How does it work?
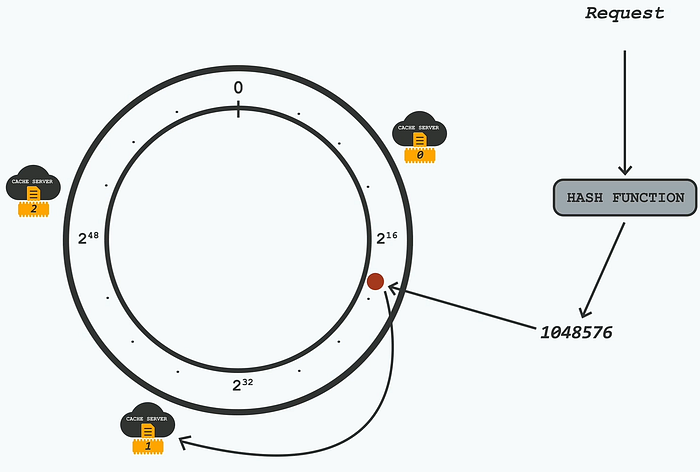
1️⃣ Imagine a giant number line from 0 to ²⁶⁴ (a HUGE number).
2️⃣ Each cache server is randomly assigned a spot on this number line.
3️⃣ Every request (T-shirt ID) also gets a random position on this line.
4️⃣ When a request comes in, it searches for the next closest server in a clockwise direction and sends the request there. ( We can go anticlockwise as well, its a symmetrical, we have chosen clockwise for convenience)
🛠 Example: Finding the Right Server
Let’s say we have 3 servers placed on this number line:
- Server 0 at position 10
- Server 1 at position 30
- Server 2 at position 50
Now, when a T-shirt request comes in:
- If its hash is 12 → It goes to Server 1
- If its hash is 31 → It goes to Server 2
- If its hash is 55 → It goes to Server 0
If a server crashes, only its portion of data needs to be redistributed! The other servers continue serving their own requests as usual.
🛠️ How Do We Handle Server Failures?
Imagine Server 1 crashes. 😱
- All the requests assigned to Server 1 will now move to Server 2 (the next closest server).
- But Server 0 and Server 2 remain untouched! 🎯
If you remove a server all the requests which belong to it will now go to the next clockwise point. So the impact will be only be on one server it won’t be the rest of the servers and the size of the impact will just be the line segment.
✨ The best part? Only 1/N of the data is affected, instead of everything!
Now, what if we add a new server (Server 3)?
- It gets randomly placed on the number line.
- Only a small portion of requests shift from other servers to Server 3.
This is WAY more efficient than moving all the data every time a server comes or goes.
Improving Consistent Hashing: Virtual Nodes
🔹 Problem: If we only have a few servers, the distribution might not be balanced.

🔹 Solution: Each physical server gets multiple virtual nodes!
For example, if we have 3 physical servers, we pretend we have 20 virtual servers spread across the number line.
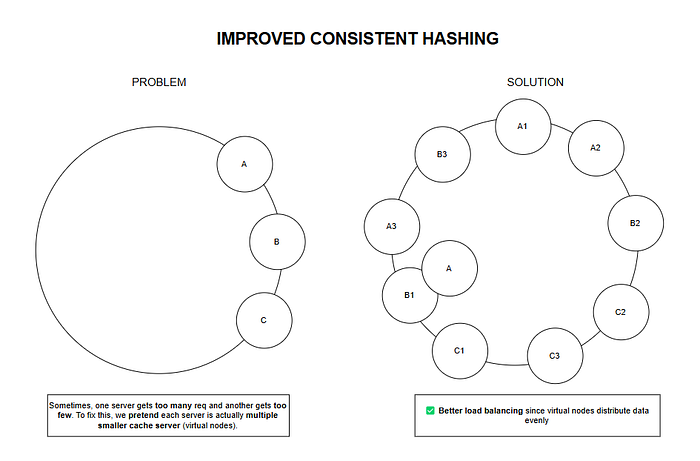
📌 Benefit?
✅ More even distribution of requests.
✅ When a server fails, its load is distributed among multiple servers, not just one.
✅ Better performance and reliability!
so thanks to Consistent Hashing we have
- Reduce Cache Warmup Time
- Increased Cache Readiness
This concept is using multiple systems for example
- Amazon dynamo db which is a database it's not a cache also uses this for reducing the amount of data migration between its database servers. In case one of the database servers crashes or has to be brought up for his horizontal scaling, the same algorithm is used.
- Redis also has consistent hashing as one of the load balancing algorithm and that it offers
- Google also uses variation of consistent hashing. It's called backend subsetting you can explore more about this.
🎯 Final Takeaways from Day 8
✅ Consistent hashing = Minimal data movement when scaling servers.
✅ Virtual nodes = More balanced load distribution.
✅ Faster cache recovery = Happier users!
At this point, you have a decent understanding of caches — you know where to place them and what algorithms can be used to distribute the load. However, we haven’t discussed how to store and retrieve data from the cache or the ideal access patterns to ensure maximum efficiency. That’s exactly what we’ll cover in the next blog.
See you in the next blog.
