Day 9: The $2000 Redis Mistake — And How to Fix It Without Losing Your Mind! 🤯
🎬 Scene: The Founder’s Panic Mode
It’s another peaceful day at your startup. The sun is shining ☀️, your servers are humming along 🎵, and the users are happily buying T-shirts.
Then… the founder storms into the room like a character in a Hollywood movie. 🎭
Founder: “We need to talk. Now.”
You: “Uh-oh. What happened?”
Founder: “Why is Redis so freaking expensive?! It’s costing me $2000 a month! I thought caching was supposed to save us money!”
💀 Boom. Mic drop. Panic ensues.
🧠 The Engineer’s Instincts Kick In
You take a deep breath. $2000 for Redis? That sounds fishy. Something is clearly wrong.
So, like a detective from Sherlock, you start investigating. 🕵️♂️
Now the engineer in you is coming out and thinking of all the possible ways of this chaos. Lets ask the right questions…
📌 Step 1: “How many Redis instances are we running?”
📌 Step 2: “What kind of data are we caching?”
📌 Step 3: “Are we using caching correctly, or is our system just hoarding data like a dragon guarding treasure?” 🐉
Your Findings After Investigating Redis Usage
During your Q&A session with the founder and team, you discover that they’re running three large Redis instances 🤯, each dedicated to a different type of data.
At this point YOU ARE QUESTIONING, Why in the world we are using 3 large instances, WHY??? 😤😤😤. The founder explains we hace three different types of data for caching :
🏆 1. Most Popular T-Shirts

- Users want to see the all-time favorite T-shirts — the ones that never go out of style.
- This data doesn’t change frequently, yet it’s being recomputed and fetched every single time instead of being stored properly in Redis. 🤦♂️
🆕 2. New Arrivals
- Some users want to grab the freshest T-shirts before anyone else.
- The system stores recently added T-shirts in Redis, which makes sense… but is it being updated efficiently?
👀 3. User’s Recently Viewed T-Shirts
- Each user has a personalized list of the T-shirts they’ve viewed.
- The issue? Every time a user views a new T-shirt, the entire object is stored in Redis — including metadata, descriptions, images, etc., instead of just storing the T-shirt ID. 🤯
At this point, you have a pretty good idea of what’s being stored, and now it’s time to guide the engineering team to fix all the issues with this.
🏆 Mistake #1: The Cache That Wasn’t a Cache
Diagnosis: The engineers were still querying the database every time they needed to find the most popular T-shirts.
You’re running an SQL query on the database instead of using the cache. This means every time a user requests the most popular T-shirts, the system queries the database to fetch the view count for each T-shirt.
Developers are concerned about data consistency — they worry that if the view count in the cache becomes outdated, it might not match the actual value in the database. To avoid this, they are bypassing the cache and querying the database directly, which defeats the entire purpose of caching. 🤦♂️
Reality Check:
If you’re still hitting the database for every query, what’s even the point of caching? 🤦♂️
📌 Solution: Store precomputed results in Redis and refresh them every few hours.
📌 Why it works: Users don’t need up-to-the-second accuracy for “most popular T-shirts” — an update every hour is just fine.
🤯 Mistake #2: The Elephant-Sized Objects in Redis
Diagnosis: Every user’s T-shirt history was being stored with full metadata in Redis.
Imagine stuffing an entire Amazon product page into your brain every time you think about a T-shirt. That’s what our cache was doing.
👎 What they did:
"user_123_recent_views": [
{
"id": "tshirt_1",
"name": "Super Cool T-shirt",
"description": "This is a really awesome T-shirt",
"price": "$19.99",
"color": "black",
"size": "L",
"images": ["url1", "url2"],
"brand": "FancyBrand"
},
{
"id": "tshirt_5",
"name": "Another Cool T-shirt",
"description": "A must-have!"
}
]Holy database bloat! 🤯
✅ What they should have done:
"user_123_recent_views": ["tshirt_1", "tshirt_5"]Because cache memory is very expensive. You want to keep the objects light.
Just store the IDs! The metadata can be fetched separately.
🔥 Mistake #3: The Cache That Never Expires
Diagnosis: Redis was hoarding data like it was preparing for a zombie apocalypse. 🧟
Reality Check:
Caches are like refrigerators. If you never throw anything out, it starts smelling bad.
✅ Solution: Implement cache expiry using TTL (Time-To-Live).
This way, we don’t store stale data forever. We need to expire and updat e the cache on specific interval.
🤖 The Engineer’s Redemption Arc
Now that you’ve identified the problems, you gather the team and explain:
💡 Caches are here to speed things up, not store the entire database in RAM!
- Precompute heavy queries & cache results.
- Store lightweight data (IDs, not full objects).
- Use TTL to keep Redis from becoming a junkyard.
🎉 The founder checks the Redis bill a week later — boom, costs dropped by 70%.

🙌 Victory! You’ve saved the company thousands of dollars and earned yourself eternal developer respect.
🏆 Before You Celebrate Your Victory… Let’s Talk About Caching Like a Pro!
So, you’ve been flexing your caching skills like a boss, optimizing queries, reducing costs, and making the founder happy. But before you break out the confetti, let’s talk about one last piece of the caching puzzle — how do you keep cache updated without it turning into a chaotic mess? 🤯
Cache Has Trust Issues 🤨
Caching is like that one friend who remembers things but never updates them — so they keep telling you outdated gossip. 😅 If not handled well, your cache might serve stale data, making it out of sync with the database.
But don’t worry! Redis comes with built-in update policies that help maintain order. Let’s dive into them.
📝 Write Policy 101: Keeping Your Cache & Database in Sync
Think of caching as a diary where you store quick notes before updating the official records. How you write in that diary determines how accurate it is compared to the original.
There are two major ways to keep the database and cache in sync:
🏃♂️ 1. Write-Through Policy: The Safe but Slower Route
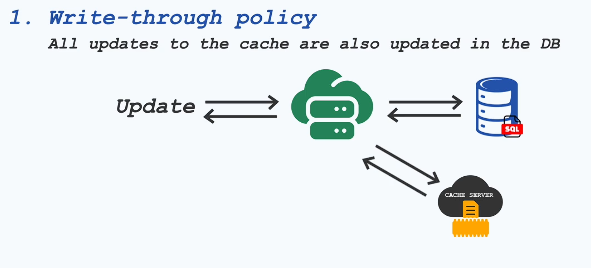
🛠 How it works:
- Every time an update happens, you immediately update both the cache and the database.
- The database must confirm the update before the cache is modified.
📌 Example:
Imagine you’re running a T-shirt store. Every time someone buys a T-shirt, the system:
1️⃣ Updates the database (reducing stock by 1).
2️⃣ Updates the cache (so the app shows the correct stock).
3️⃣ Only then does it return a response to the user.
🔴 Downside?
- Since every update requires a database write, it adds extra load to the database.
- Might slow down responses, especially for high-traffic applications.
🟢 Good for:
- Critical data like bank transactions, where consistency is non-negotiable.
⏳ 2. Write-Behind Policy: The Lazy Genius

🛠 How it works:
- Updates go to the cache first instead of the database.
- The database is updated later, usually when the cache entry is evicted (removed due to space constraints).
📌 Example:
Imagine tracking T-shirt views. Instead of updating the database every time someone sees a product, you:
1️⃣ Update the view count in Redis (fast ).
2️⃣ When Redis runs out of space and removes old entries, the system adds the total views to the database in one go (instead of every single time).
🔴 Downside?
- If Redis crashes before syncing, you lose recent updates (oops 🤦).
- Not great for critical data (like payments).
🟢 Good for:
- Less important, high-frequency updates (e.g., product views, click counts).
- Reducing load on the database while keeping the cache blazing fast.
Interesting ways companies handle Cache system
The other thing that you can do with the cache is you can treat the cache as a separate entity and the database as a separate entity.
Option 1: Cache & Database as Separate Entities (The Independent Duo)
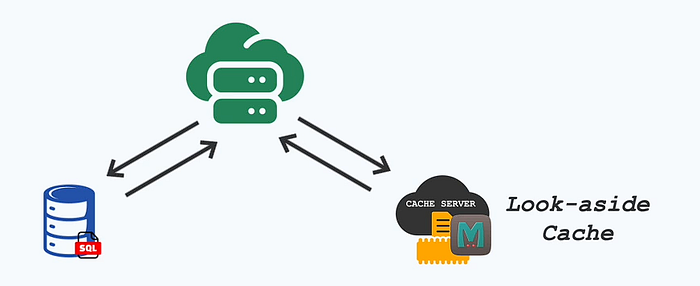
💡 How it works:
- Your app talks directly to the database for updates (SQL queries, transactions).
- Your app also talks directly to the cache (like Redis) for updates when needed.
- When reading data, it can choose whether to hit the cache or database — this depends on the logic you implement.
📌 Example:
Let’s say you’re running T-shirt eCommerce (again! 🏪).
1️⃣ When a user views a T-shirt, the app checks the cache first.
2️⃣ If it’s not there, the app queries the database directly.
3️⃣ Instead of Redis handling the population, the app itself decides when to update the cache.
🔴 Why this approach?
- Gives the developer full control over caching logic.
- Used when complex business logic determines how cache entries are refreshed.
- Facebook’s Memcached system follows this pattern — where the cache is separate from the database.
Option 2: Cache Handles Database Lookups
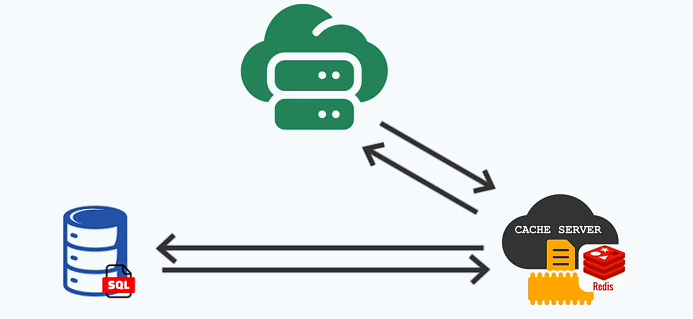
💡 How it works:
- Your app always queries the cache first.
- If the cache doesn’t have the data, Redis itself fetches it from the database, stores it, and returns it to the app.
- The cache automatically populates itself instead of relying on the app to do it manually.
📌 Example:
You’re back at your T-shirt store 🛒.
1️⃣ A customer asks for a T-shirt’s stock count.
2️⃣ Cache checks if it has it — if yes, it returns it immediately.
3️⃣ If not, Redis queries the database, saves the result, and returns it.
4️⃣ Next time someone asks, boom! Cached result = instant response.
🟢 Why this approach?
- Less code for developers (Redis does the heavy lifting).
- Easier to implement than managing cache logic yourself.
- More efficient for frequently accessed data.
Enjoyed this? Smash that share button or drop a comment below with your caching horror stories!
🔔 Follow along so you don’t miss it! See Yaa in the next blog. 👋
