Day 4: Debugging, Monitoring, and Ensuring System Reliability!
Welcome Back, Fellow Builders!
Wow, you’re really in deep now, aren’t you? 😏 The fact that you’re here means you’re starting to think like a systems architect — spotting problems before they become disasters and making sure everything runs smoothly even when things inevitably fail.
But today, we’re going to shake things up! 🎢
Before moving forward, here are the final reference blogs for this series, in case you’d like to start with them:
3. System Design — Day 3 : Bringing Your E-Commerce App to Life! | by Yash Verma | Feb, 2025 | Medium
Awesome. Here we go.
Your current system architecture looks like this :

Imagine this: You’ve built your dream e-commerce website. It’s deployed. It looks awesome. Customers are registering, logging in, placing orders — everything’s going perfectly…
Until it isn’t. 😨
🔥 The Chaos Begins: “My Payments Are Failing!”
A week after launch, your founder rushes back to you in panic mode:
“We had a ton of orders last week, but some payments didn’t go through! Customers are frustrated, and we don’t even know why. Can you figure this out?” 😱
First instinct as an engineer? 🕵️♂️
Let’s diagnose the issue.
You check the payment gateway’s agreement, and they guarantee a 98% success rate. That means 2% of transactions are expected to fail due to network issues, bank declines, or other external factors.
The Real Problem? Lack of Visibility
The bigger issue isn’t that payments failed — it’s that no one could debug what went wrong fast enough.
Your founder and customer support team are flying blind. They need a way to:
✅ Trace failed transactions quickly.
✅ Identify patterns in failures.
✅ Provide clear answers to frustrated customers.
This is where system observability comes in.
🔍 Step 1: Logging & Monitoring
When something important happens in your system, it needs to be logged.
1️⃣ Request In → Log the request.
2️⃣ Critical Operations → Log database writes, API calls, and external requests.
3️⃣ Response Out → Log the response with a unique request ID.
💡 Why is this powerful?
If a customer says, “My order didn’t go through!”, you can:
- Search logs for their email or order ID.
- Find out exactly where things broke.
- Fix the issue faster than ever.
🛠️ Tools for Logging & Monitoring
✅ AWS CloudWatch (For AWS Lambda & EC2 logging)
✅ Google Cloud Logging (For GCP users)
✅ Azure Monitor (For Azure-based systems)
Now, your team can query logs with regex searches and trace failures in seconds!
📌 Result?
✅ Faster debugging
✅ Fewer support tickets
✅ Happier customers & a stress-free team
📊 Step 2: Observability & Anomaly Detection
Logging tells us what happened in the past. But how do we spot issues in real-time?
Your founder wants to know:
- How many orders were placed today? 📈
- Are sales dropping? 📉
- Is something broken right now? 🤔
Solution: Build a Dashboard!
Instead of waiting for angry customer emails, we:
✅ Track trends with a real-time dashboard.
✅ Spot unusual activity (e.g., 100 daily orders → suddenly 10 today 😨).
✅ Investigate anomalies immediately.
🛠️ Tools for Dashboards & Analytics
✅ Google Analytics (Basic tracking)
✅ Power BI, Tableau (Advanced analytics)
✅ AWS CloudWatch Metrics (For cloud-hosted apps)
📌 Result?
✅ Data-driven decision-making
✅ Proactive issue resolution
✅ Less stress for everyone
🛑 Step 3: Preventing Failures Before They Happen
Okay, we’ve fixed the immediate chaos. But what about the next disaster?
Instead of reacting, let’s design for failure resistance from the start.
⚠️ Spotting Critical Failure Points
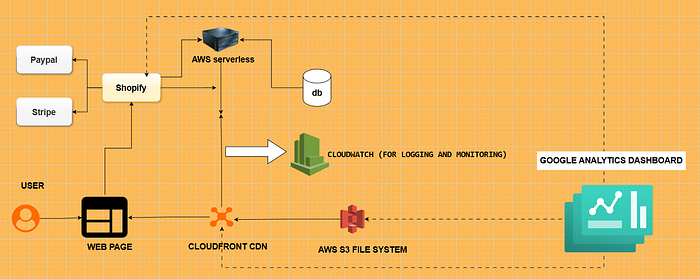
Look at this high-level system diagram of our e-commerce app:
🖥️ Frontend (CDN — AWS CloudFront)
🔗 API (AWS Lambda)
💾 Database (AWS RDS)
💳 Payment Gateways (Stripe, PayPal)
📦 Third-Party Integrations (Shopify, Delivery APIs)
Now ask yourself:
🤔 What happens if a key component goes down?
💀 If CDN fails → No web pages load → No orders
💀 If Server crashes → Everything stops working
💀 If Shopify API is down → No new orders get processed
💀 If Stripe fails → Customers can’t pay
Welcome to the world of fault tolerance! 🎢
🛡️ Step 4: Making the System Resilient
✅ Backups → Always have a secondary database copy.
✅ Failover Servers → AWS auto-restarts serverless instances if they crash.
✅ CDN Reliability → AWS CloudFront has multiple backup servers globally.
✅ Multiple Payment Gateways → Use Stripe + PayPal (if one fails, switch to the other).
We can have backup for everything, but that brings a lot of things on the table. Thats a lot of work, we need to create backup after backup until we realize that if even the backups fail, what will we do? The solution is Graceful Degradation.
✅ Graceful Degradation → Show useful error messages instead of letting things break.

🔚 Wrapping Up: What Did We Achieve Today?
🎯 Added Logging & Monitoring → Faster debugging, fewer support tickets
🎯 Built Dashboards for Observability → Found issues before customers did
🎯 Designed for Resilience → Prepared for failures before they happen
FINAL ARCHITECTURE:
We’re just getting started. See you in the next blog! Let’s make our system even better! 💪
